|
Vighnesh Subramaniam I am a second year MIT EECS PhD student at CSAIL advised by Boris Katz in the MIT Infolab. I also work closely with Brian Cheung and previously worked with Andrei Barbu. Before my PhD, I obtained my bachelors (2023) and MEng (2024) in Computer Science at MIT. During this time, I was a research assistant in the Infolab specifically working on problems in deep learning, multimodal processing, and computational neuroscience. During my MEng, I also had the opportunity to work on research with Shuang Li, Yilun Du, Igor Mordatch, and Antonio Torralba on problems related to generative modeling. I am extremely fortunate to be supported by the NSF Graduate Research Fellowship as well as the Robert J Shillman (1974) Fund Fellowship. |

|
ResearchMy research focuses on deep learning architecture design, investigating the relationship between neural network architectures, transferring properties from one architecture to another via representational alignment, as well as designing new training algorithms for neural networks. I also think a lot about neural networks with nice theoretical/compute properties that are difficult to optimize and how to improve them. In the past, I conducted research on many topics, including multimodal models, finetuning with large language models, and deep learning applications to neuroscience/cognitive science. I highlight some publications below -- see my scholar for a more complete list. |
|
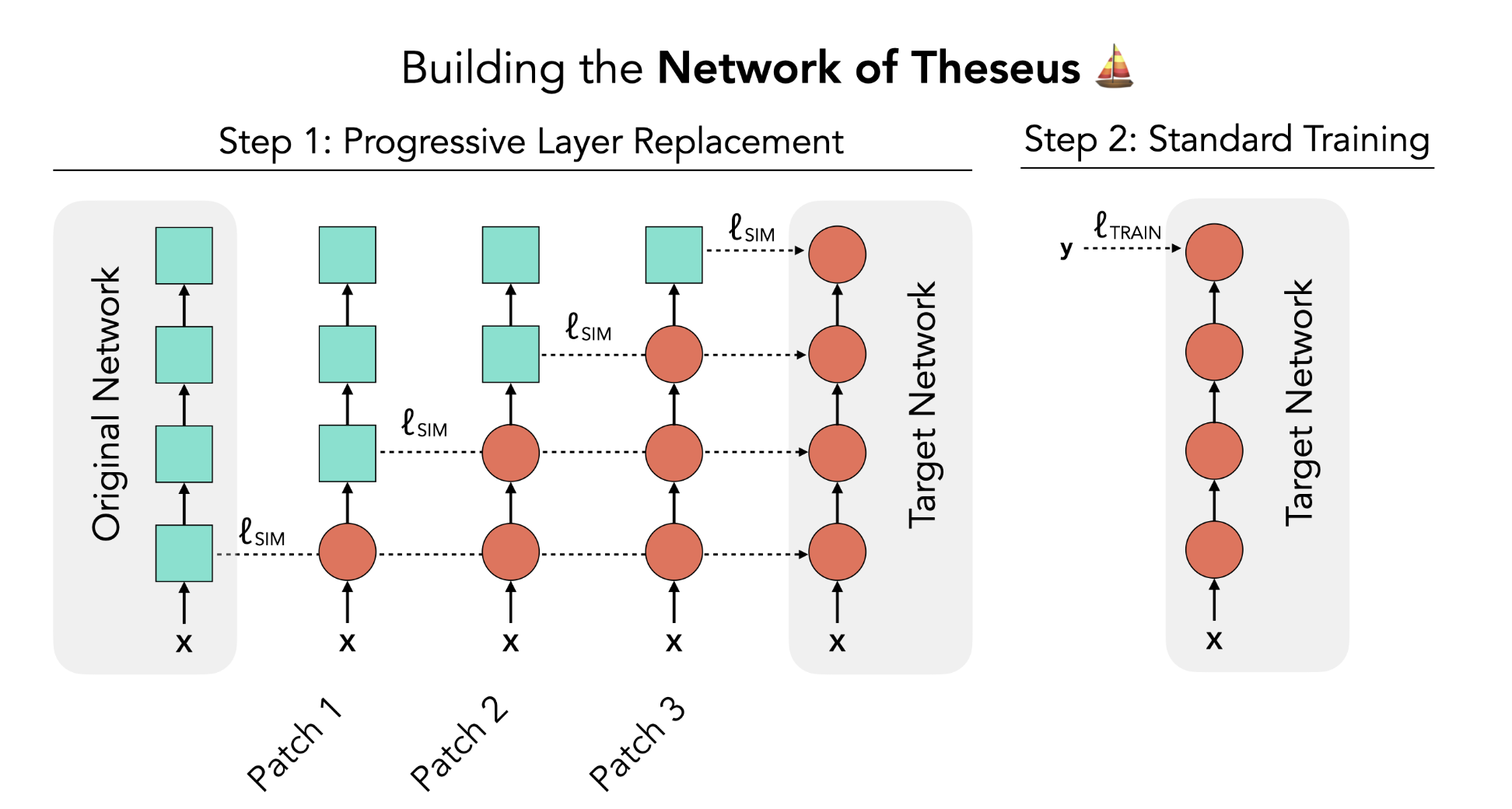
**NEW** Network of Theseus (like the ship)
Vighnesh Subramaniam, Colin Conwell, Boris Katz, Andrei Barbu, Brian Cheung Under Review arXiv We introduce the Network of Theseus (NoT), a method to part-by-part convert between architectures. We show massive conversions where untrained architectures can be used to guide a conversion to a completely new architecture. This leads to some pretty amazing findings on RNNs and MLPs. Furthermore, we find some even more striking results for making larger architectures smaller using untrained teachers! |
|
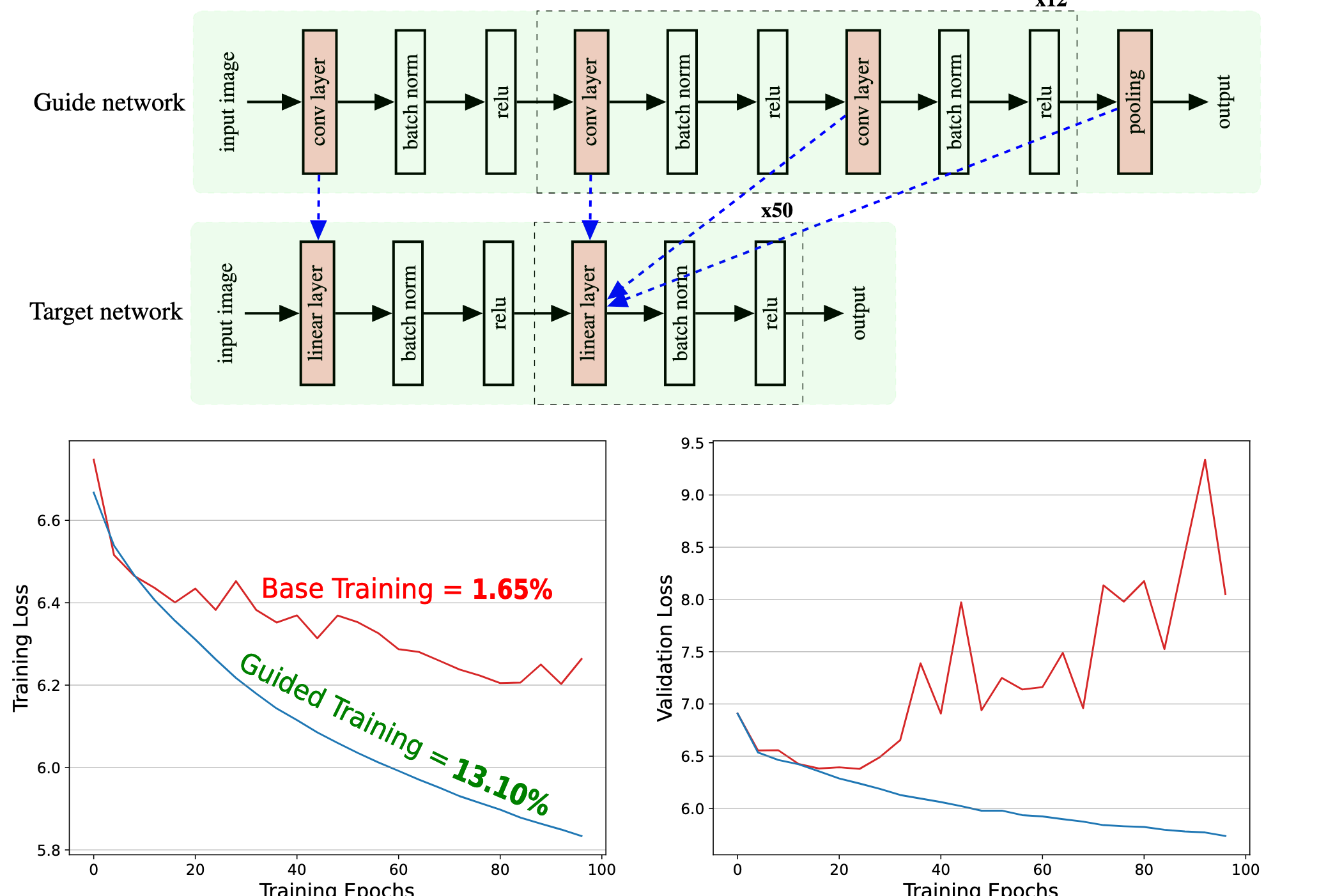
Training the Untrainable: Introducing Inductive Bias via Representational Alignment
Vighnesh Subramaniam, David Mayo, Colin Conwell, Tomaso Poggio, Boris Katz, Brian Cheung, Andrei Barbu Neural Information Processing Systems, 2025 Neural Information Processing Systems: Workshop on Unifying Representations in Neural Models, 2024 Project Page / arXiv / Code We investigate the relationship between inductive biases in neural networks and their representation space by designing methods to transfer aspects that make certain networks trainable to networks that are difficult to train. This is done by a per-training-step alignment of the untrainable network activations and trainable network activations. Our findings are really surprising and we make some of these networks really competitive like RNNs! |
|
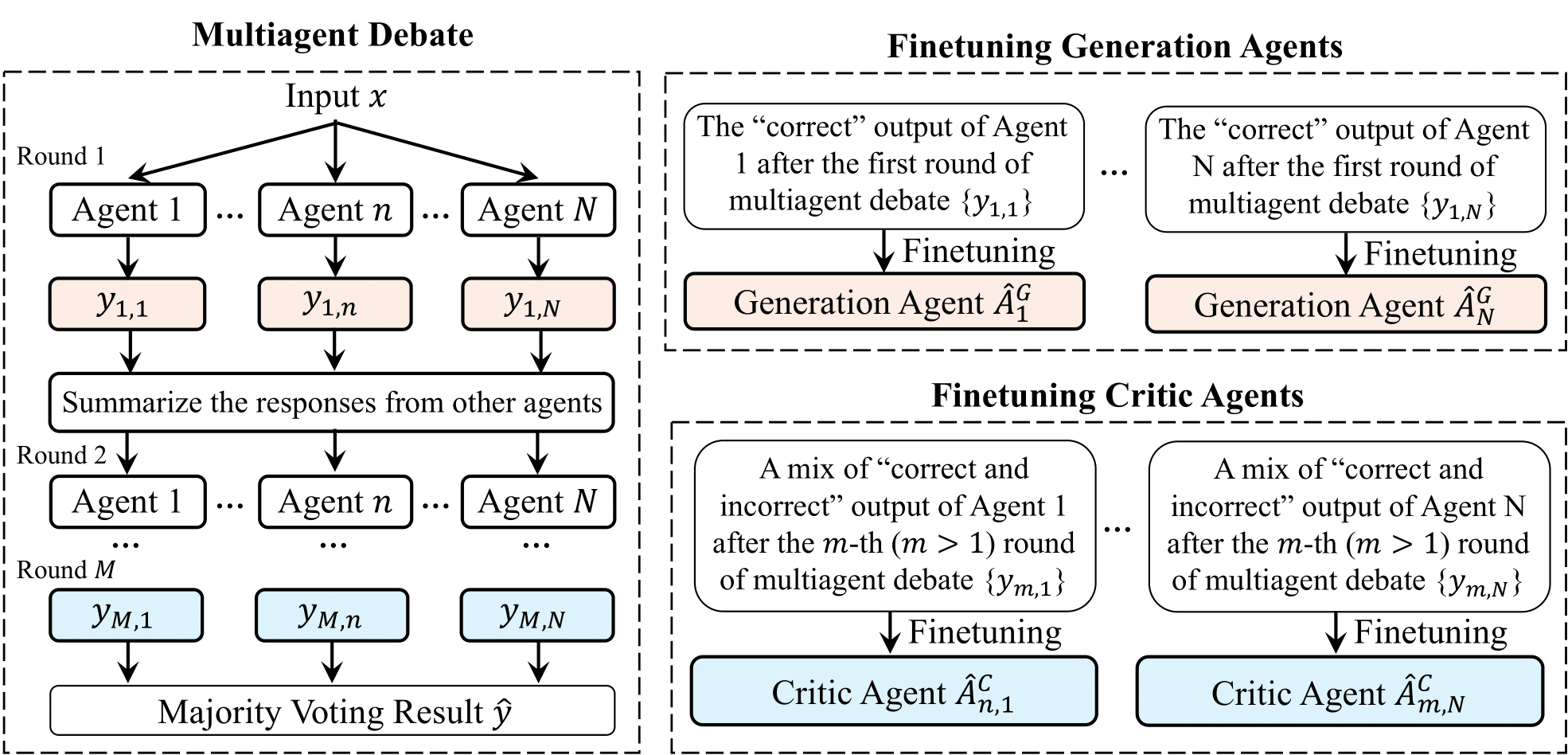
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Vighnesh Subramaniam*, Yilun Du*, Joshua B. Tenenbaum, Antonio Torralba, Shuang Li, Igor Mordatch International Conference on Learning Representations, 2025 Project Page / arXiv / Code We designed a new self-improvement finetuning method for LLMs that preserves diversity. Our method builds on multiagent prompt frameworks like multiagent debate but finetuning sets of generation and critic models that interact by proposing more accurate solutions and critiquing solutions more accurately. We see pretty considerable improvements across several math-related tasks! |
|
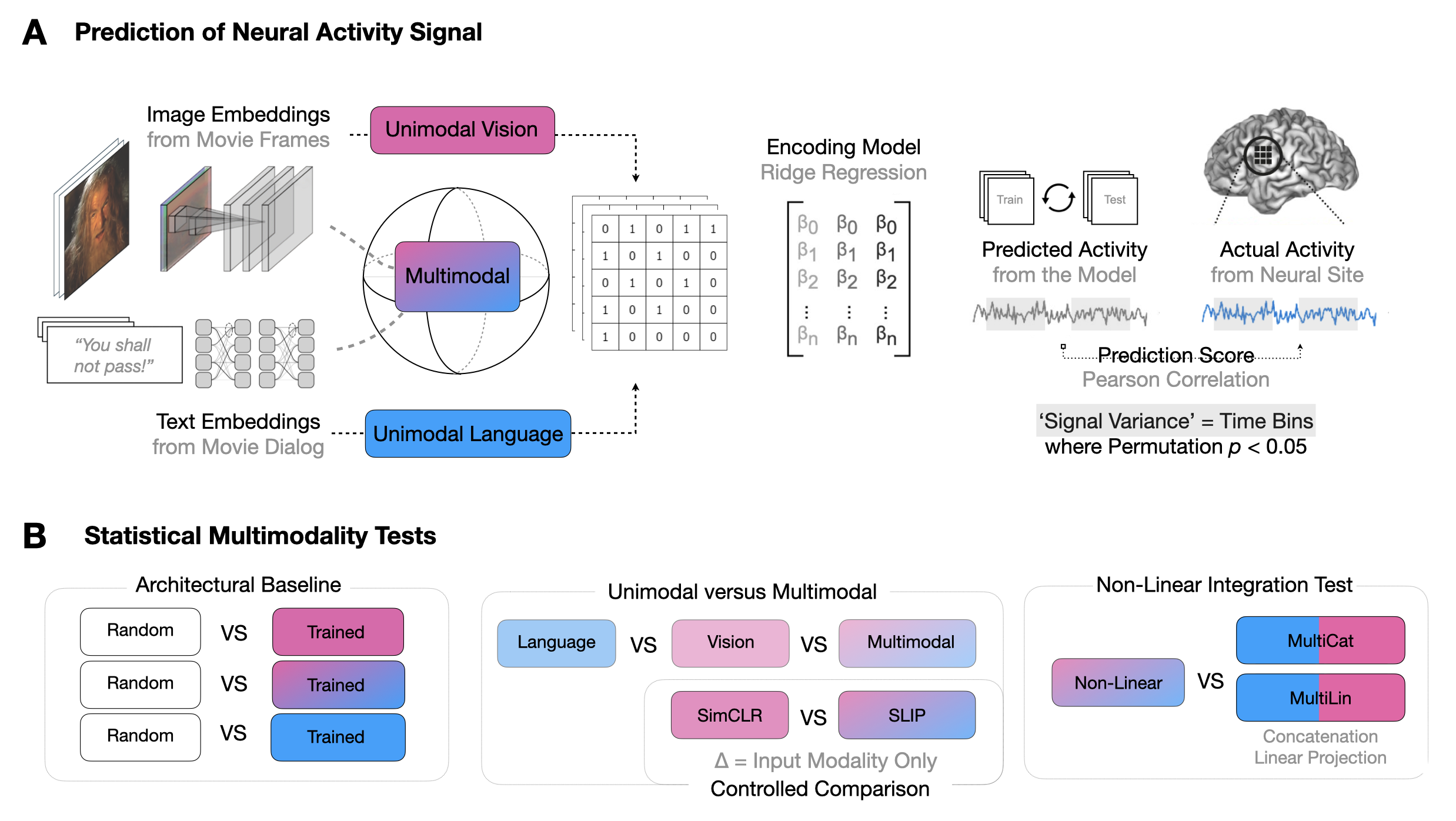
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Vighnesh Subramaniam, Colin Conwell, Christopher Wang, Gabriel Kreiman, Boris Katz, Ignacio Cases, Andrei Barbu International Conference on Machine Learning, 2024 International Conference on Learning Representations: Workshop on Multimodal Representation Learning, 2023 Project Page / arXiv / Code Multimodal deep networks of vision and language are used to localize sites of vision-language integration in the brain and identify architectural motifs that are most similar to computations in the brain. |
|
Website design credits to John Barron. |